
ここでは、高精度で使いやすい、当社の外観検査装置StaVaTesterII(スタバテスタ・アイ・アイ)をご紹介します。
StaVaTesterIIは統計とパターン認識技術を使用する外観検査装置で、外観検査の全自動化・半自動化に対応できます。また、ルールベース方式の外観検査装置と比較すると、製品のばらつきに強く検査精度が高いため、検査精度でお困りの場合は、StaVaTesterIIを是非ご検討下さい。
以後、以下の項目についてご紹介します。
1)StaVaTesterIIの位置づけ
2)StaVaTesterIIの詳細説明
3)ルールベース方式外観検査との比較
StaVaTesterIIの外観検査における位置づけ
製造工程における検査の自動化
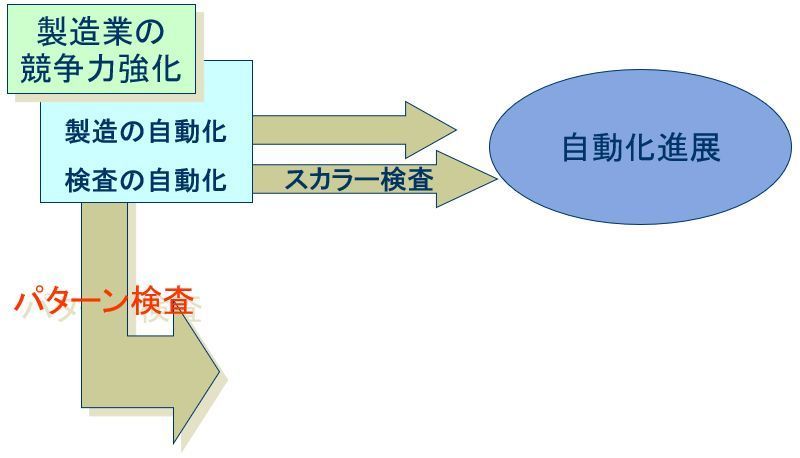
製造業の競争力を維持向上させるためには、製造コストの低減が不可欠です。このためには、製造の自動化と検査の自動化が避けて通れません。
製造の自動化についてはかなり進展していますが、検査についてはまだ改善の余地があります。
検査はスカラー検査とパターン検査に大別できます。スカラー検査は製品の重量や寸法など、測定値が1つの簡単な測定を基にした検査で、自動化が容易なため既に自動化が進展しています。
しかし、製品の外観検査や自動車エンジンの異音検査などのパターン検査は、自動化が難しいため自動化は進展していません。
製造工程における自動化
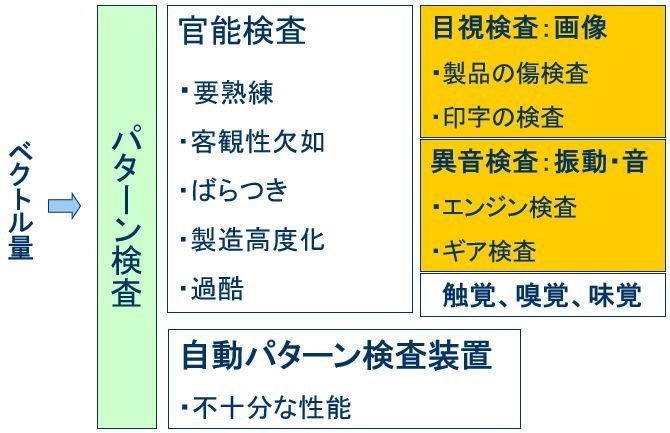
パターンとは波形や画像などの時間的空間的情報のことで、通常はベクトル量で表すことができます。パターン検査はパターンに基づく検査であり、スカラー検査と比較すると格段に難しいといわれています。このため、パターン検査は人間の視覚や聴覚を利用したいわゆる官能検査に頼る場合が多いのが現状です。
しかしながら、官能検査には以下の問題点があります。
・熟練を要する。
・検査結果に客観性がない
・人により、また同一検査員でも結果にばらつきが生じる。
・製品の高度化、製造の高度化により人間では対応できにくくなりつつある。
・人間にとって過酷な業務である。
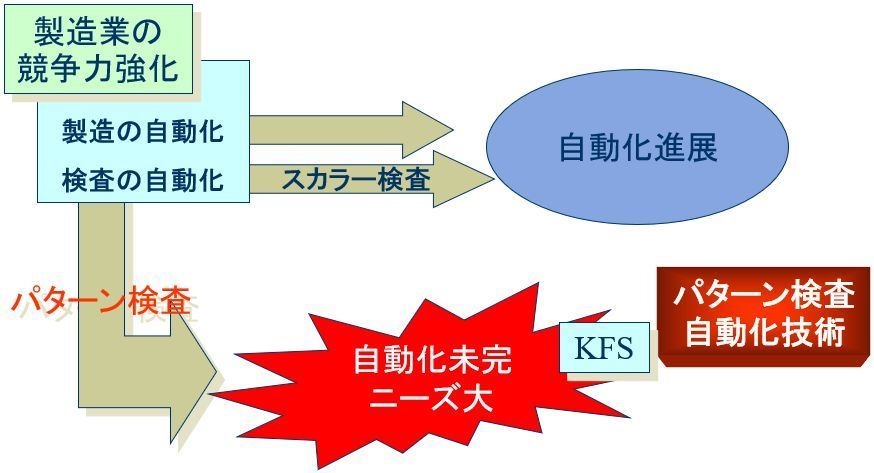
このように、パターン検査の自動化ニーズは強いものの、十分な検査精度を持つ自動検査装置は少ないのが現状です。
パターン検査の現状
以上のように、パターン検査の自動化はものづくりにおいて大きなニーズがあります。また、キーの1つはパターン検査技術であると考えられます。
パターン検査のキー技術
パターン検査とは
それでは、なぜパターン検査が難しいのでしょうか。これ以降、この点について説明します。
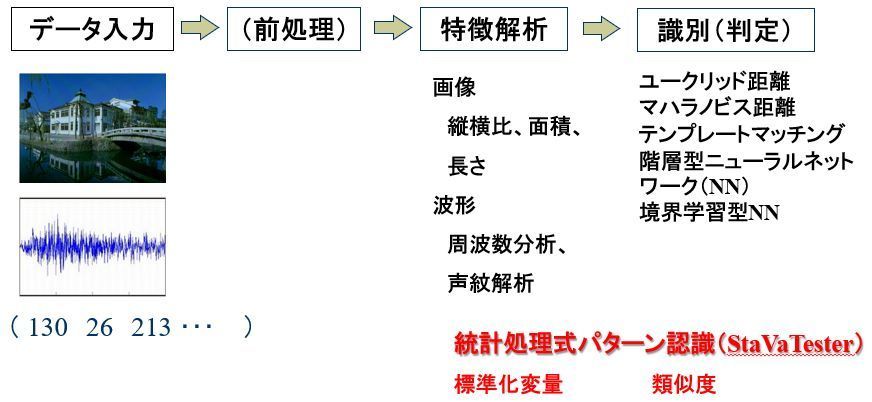
パターン検査は通常パターン認識技術と呼ばれる技術を使用し、検査を行います。検査は、以下の順で行われます。
「データ入力」→「前処理」→「特徴解析」→「判定」
データ入力は判定精度に大きな影響を与えるため、画像に関する知見や波動に関する知見を有効に利用して収集する必要があります。
前処理はノイズを低減する必要がある場合に行われます。
特徴解析は、元々のパターン情報には冗長性がありデータ量が膨大である一方、一般の識別技術では取り扱えるデータ数に限りがあるため、特徴を損なうことなく元データを圧縮するために行われます。例えば、画像を使用して魚種を判定する検査では、魚の縦横比などを特徴量とする方法が使われたこともあります。縦横比を使えば、タイとイワシの識別は容易です。
最後に、特徴量に対して識別技術を適用して判定を行います。識別技術として、これまで解析的な方法(ユークリッド距離、マハラノビス距離、テンプレートマッチングなど)や階層型ニューラルネットワーク(NN)、境界学習型NNなどが使用されています。
解析的な方法ではカテゴリの境界を直線で表す能力しかないため(線形分離)、過検出や見逃しが防げず、帯に短したすきに長しという状態でした(または、オオカミ少年)。
そこにNNが導入され、カテゴリ間の境界が曲線になるため(非線形分離)非常に期待されましたが、これにも問題があることがわかり、NNも下火になりました。しかし、境界学習型NNが開発され、実用的なパターン検査装置が実現しました(当社の竹田が前職時に開発し実用化しました)。
ところが、依然として特徴量の数が多いと適用が難しいため、境界学習型NNを外観検査に適用することはできませんでした。そこで、当社が統計処理式の検査技術を開発し、外観検査においても境界学習型NNと同程度の精度を持つ検査を可能にしました。
パターン検査のフロー
それでは、検査精度の性能にとって重要な過検出と見落としについて説明します。
これまでのパターン検査では、識別技術として解析的な方法が使用されています。すると、検査性能にとって致命的といえる問題が生じます。下図は、検査品が良品であるか不良品であるかを検査する装置の精度を説明したものです。この装置では良品であれば1を出力し、不良品であれば0を出力すものとします。この時、この装置により実際に検査をすると、検査時にどのような検査出力が出るかを示したものです(頻度分布)。良品に対しては比較的大きな出力、不良品に対しては比較的小さな出力を出し、それなりの結果を出します。しかし、一般に良品に対する頻度分布曲線と不良品の頻度分布曲線は交差します。そこで、上記2つの曲線がオーバーラップするところの出力が得られた場合は良品か不良品かの判断ができません。原理的には検査は不可能です。
しかし、他に検査方法がなければこれを何とか使わざるをえません。そこで、閾値を設定して出力がこの値より大きければ良品、小さければ不良品と無理やり決めることになります。この結果、過検出や見落としが避けられません。
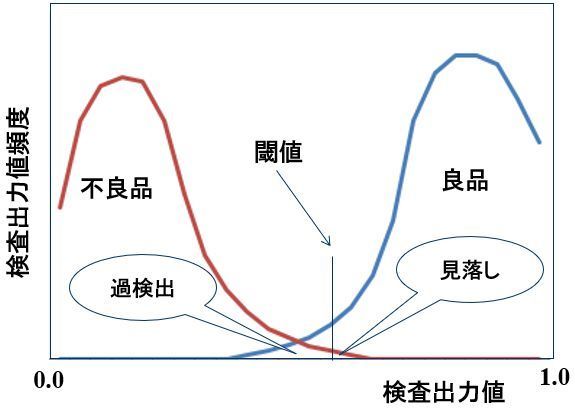
一般的なパターン検査装置の検査精度
以上のように、頻度分布曲線のオーバーラップが発生する理由を、図を使い説明します。
いま、手書き文字「a」「b」を各種の識別技術を使用して認識することを考えます。なお、「c」は学習しません。
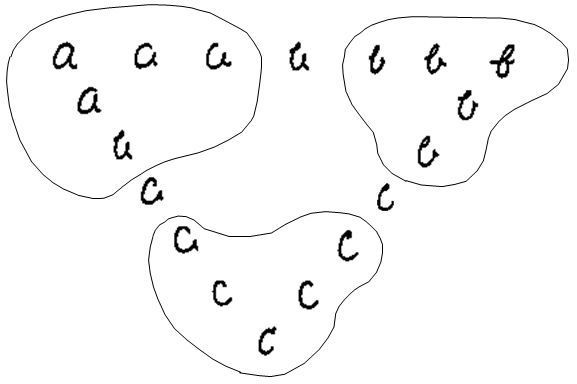
手書き文字の認識
カテゴリの境界線は一般に曲線になりますが、解析的方法では線形分離しかできないため、どうしても重なる範囲やカバーできない範囲が出ます。
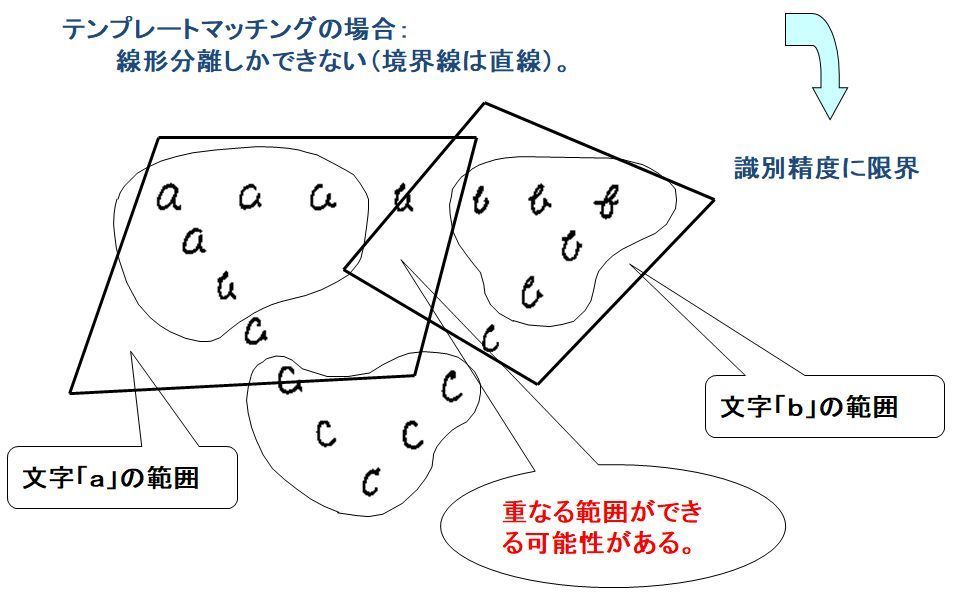
テンプレートマッチング法によるカテゴリの分離
また、データの中から選んだテンプレートがカテゴリのどの部分をカバーするか全くわかりません。従って、多数のデータに対して性能を確認する必要も生じます。ただし、[c]を判別させると、[a]であると判別したり、「b」であると判別することが極端に多く発生することはありません。
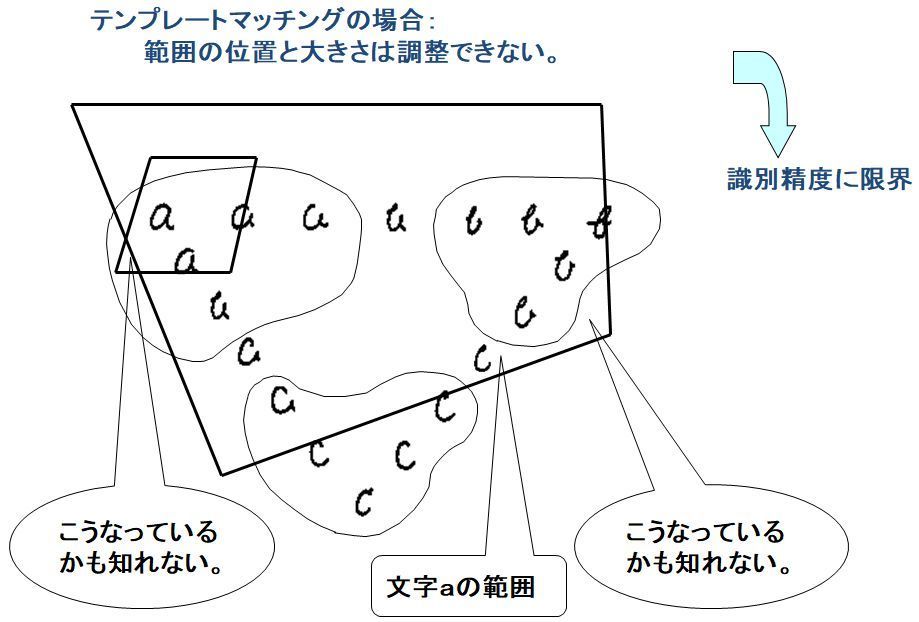
不明瞭なカバー範囲
階層型NNは非線形分離が可能であるため、学習したカテゴリは高精度で識別できます(過検出少)。しかしながら、この曲線はカテゴリを分別するための線であってカテゴリを特定するための線ではありません。このため、学習していない文字「c」を判定させると、境界線より右のものは「b」、左のものは「a」と判定しがちです(見落し極めて多)。このため、大ブームを起こしたNNが急速に下火になりました。
現在脚光を浴びているディープラーニングでは、従来のNNと比較すると性能は極めて高くなっていますが、学習していないデータに対する応答は基本的に変わりません。従って、検査応用は難しい可能性があると思います。
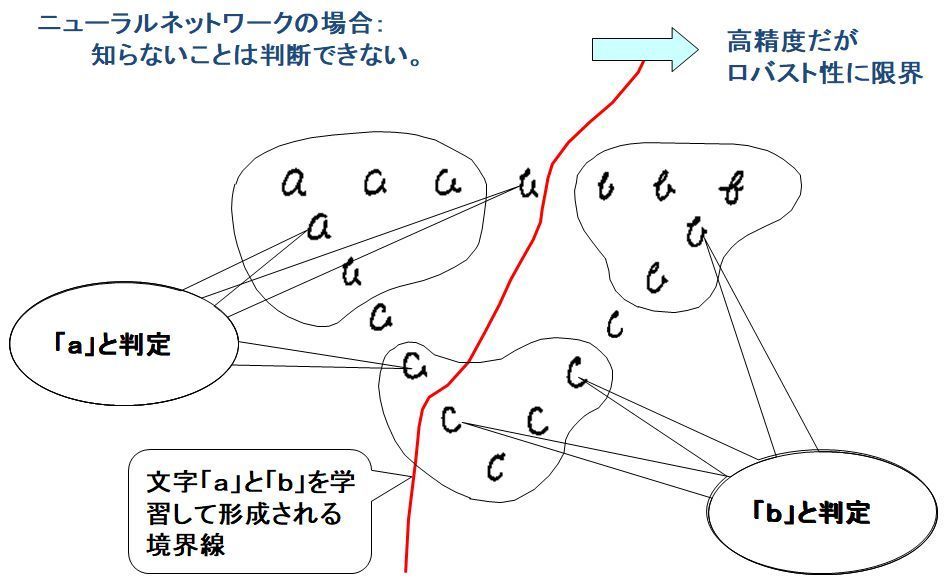
3層階層型NNによる識別
境界学習型NNはカテゴリの境界線を学習します。このため、学習したカテゴリに属するものは正しく判定します(過検出少)。一方、「c」を判定すると「a」でも「b」でもないと正しく判定します(見落し少)。このため、境界学習型NNを識別技術として使用すると良品と不良品の頻度分布曲線が交差しないことが期待されます。
実際に、境界学習型NN方式を適用して自動車用デフギア検査装置では、数十万セットの検査で間違いが生じませんでした(検査精度:99.999%以上)。また、自動車用エンジンの検査でも検査員が発見できなかった欠陥を検出しています。
一方、自動車タイヤ締結用ナットを対象にした画像検査装置では、26000画像に対する検査で間違いが生じませんでした(検査精度:99.99%以上)。
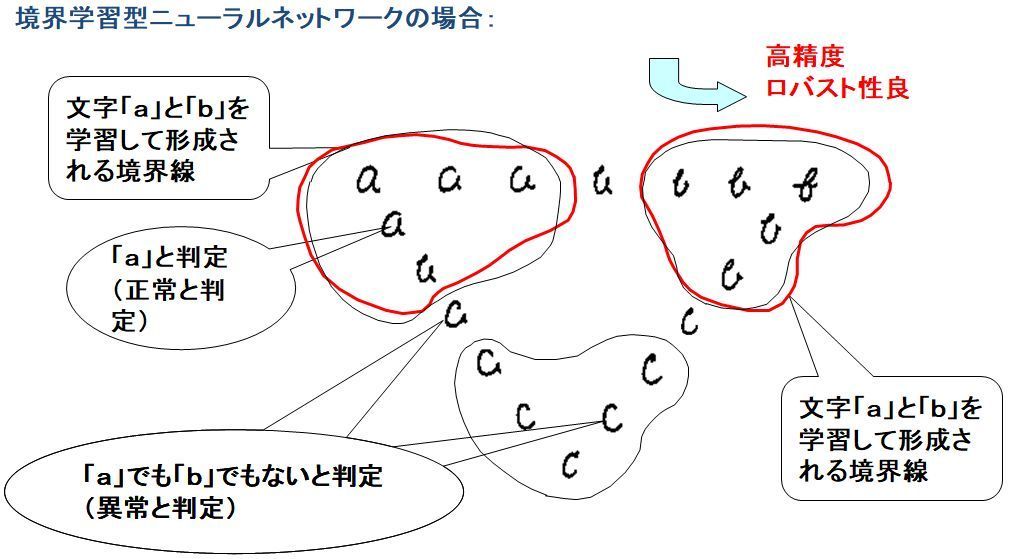
境界学習型NNが形成するカテゴリの境界線
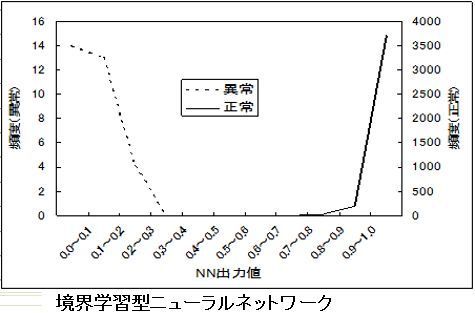
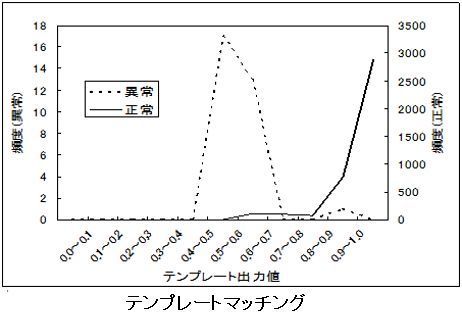
自動車用エンジン音による自動車用製品検査の検討段階での分析結果を示します。境界学習型NNを使用すると良否を判定できることが分かりましたが、同じデータに対してマハラノビス距離を適用すると良否を判定できそうにない結果が得られています。
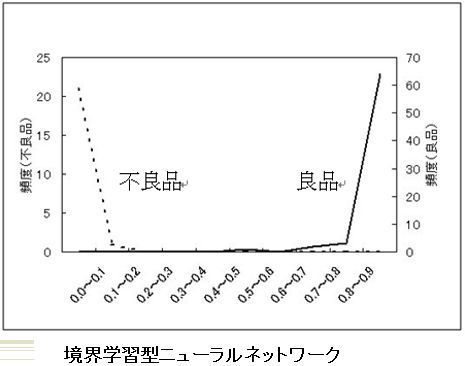
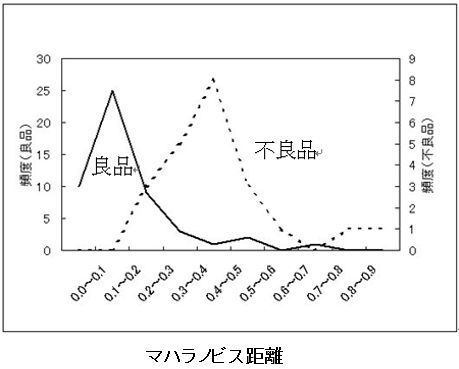
ナットの供給状態検査(異種ナットでないか、傾き過ぎでないか、裏になっていないか)においても、検討段階で境界学習型NNでは容易に判定ができる結果が得られていますが、テンプレートマッチング法を適用すると良否判定ができない結果が得られました。
以上のことから、識別方法の性能をまとめます(私見)。
識別方法の性能のうち、最も重要なもの過検出と見落としで、識別技術にはこれらの間違いが共に少ないことが求められます。解析的方法は過検出と見落としとも多くはありませんが、実用するには十分な精度とはいえません。階層型ニューラルネットワークは、過検出が非常に少ないことが特長ですが、見落しが非常に多く実際に適用できませんでした。これに対して、境界学習型NNは過検出も見落しも少なく、実用的な方法といえます。そこで、良品・不良品の頻度分布曲線が交差しなければ非常に高い検査精度が得られることが実証されたといえます。
また、StaVaTesterIIの出力の頻度分布は境界学習型のように良否で交差しない場合が多いため、高い検査精度が期待できます。ちなみに、交差しない場合は自動検査が可能で、交差する場合は半自動検査を行います。

識別の性能比較